At my current client, we use a combination of ElasticSearch and Zabbix for system and application monitoring. For your pleasure, I wrote a quick tutorial on how to set up both, and have them talk to each other. Enjoy.
Posts in "Uncategorized"
Bitcoin multinode / multiwallet test network
I put together a small repo which allows you to run a private bitcoin network. It works on top of bitcoin’s regtest capability, and uses docker to put together a small network that links a couple of bitcoin nodes. This allows you to test some bitcoin functionality that a single bitcoin regtest node can’t such as testing what happens when a transaction does not affect your wallet.
Anatomy of a geth full sync
Last week I blogged about my experiences doing a geth fast sync. The last thing I did back then was start a full sync on the same hardware. Things took a bit longer: whereas the fast sync completed in about 8 hours, the full sync took a little over 9 days. In this post my report.
Specs
I used an Azure Standard_L16s storage optimized VM. This beast has 16 cores, 128 gigs of memory and 80,000 IOPS and 800MBps throughput on its temporary storage disk. Ought to be enough you’d say. I started geth with ./geth --maxpeers 25 --cache 64000 --verbosity 4 --syncmode full >> geth.log 2>&1
Overview
| Azure VM Instance | Standard_L16s |
| OS | Ubuntu 16.04.4 LTS |
| CPU | 16 cores |
| Memory | 128GB |
| Disk IOPS (spec) | 80,000 |
| Disk throughput (spec) | 800 MBps |
| Geth version | geth-linux-amd64-1.8.3-329ac18e |
| Geth maxpeers | 25 |
| Geth cache | 64,000MB |
| Sync mode | full |
Results
| Start time | 3 apr 2018 06:26:58 UTC |
| End time * | 12 apr 2018 08:02:37 UTC |
| Total duration | 9d 1h 35m 39s |
| Imported blocks at catch up time | 5,426,156 |
| Total imported state trie entries | ? (Don’t know how to check and if that’s even relevant for full sync) |
| du -s ~/.ethereum | 244,752,908 (234G) |
* End time defined as first single-block “Imported new chain segment” log message for which al subsequent “Imported new chain segment” log messages have blocks=1
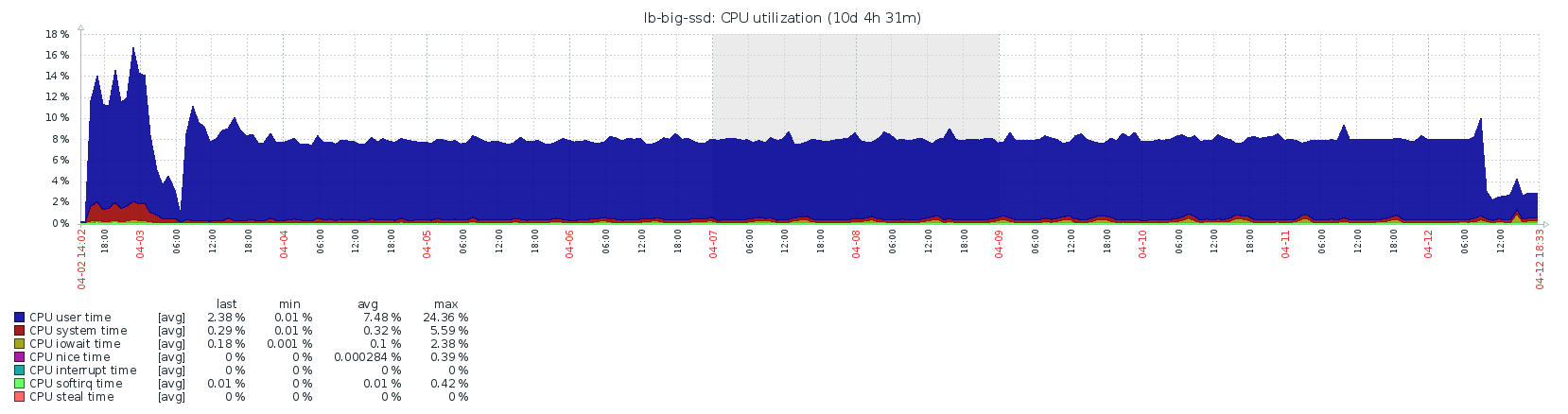
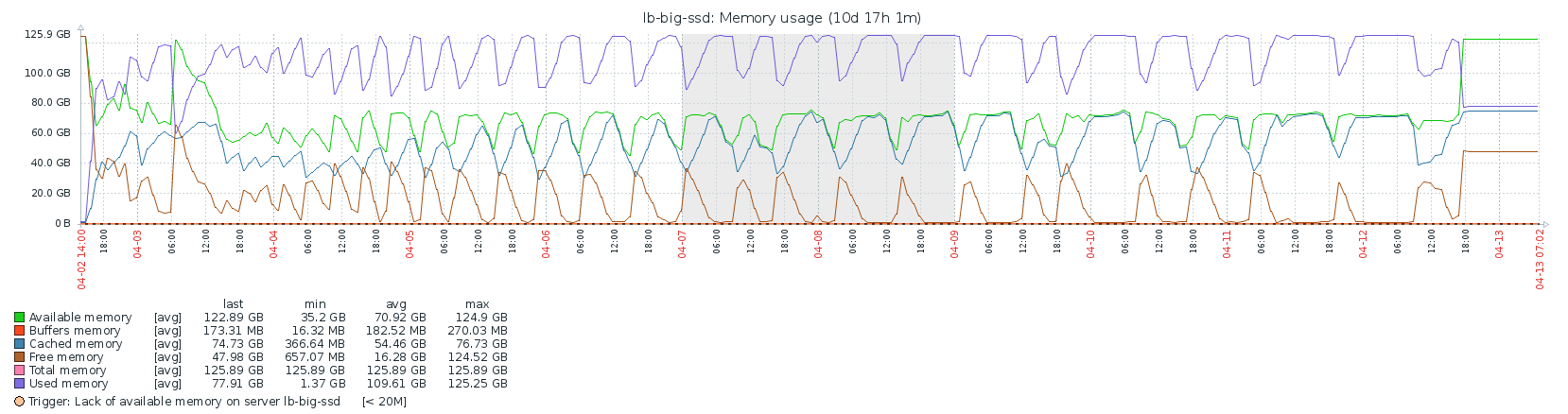
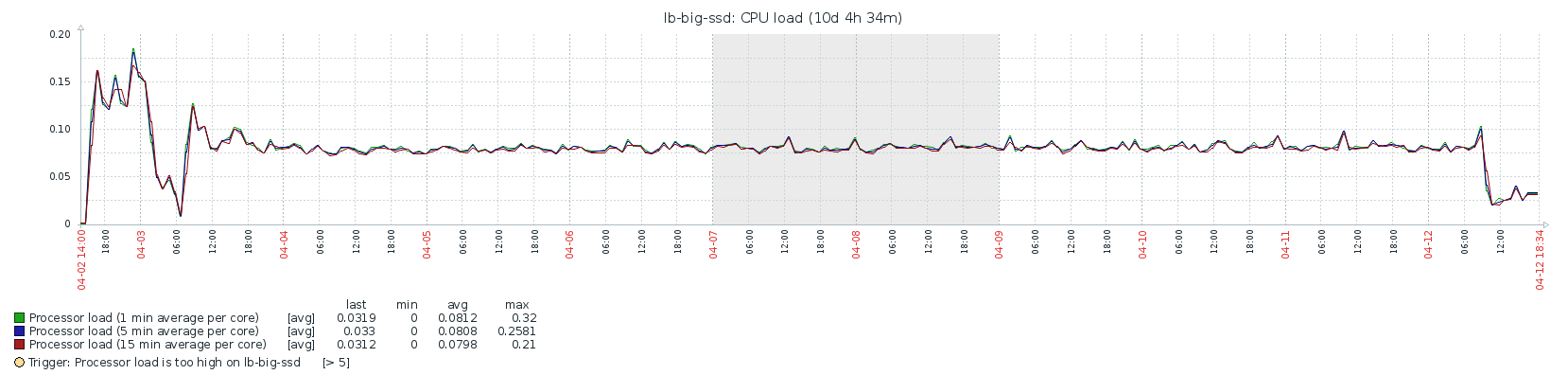
CPU/Load/Memory
(It’s too much of an effort to cut off the chart up until the actual start, so please bear in mind that it starts at 3 apr 6 utc (graph is in UTC+02:00). Sorry, let me know if someone needs more high res charts.)
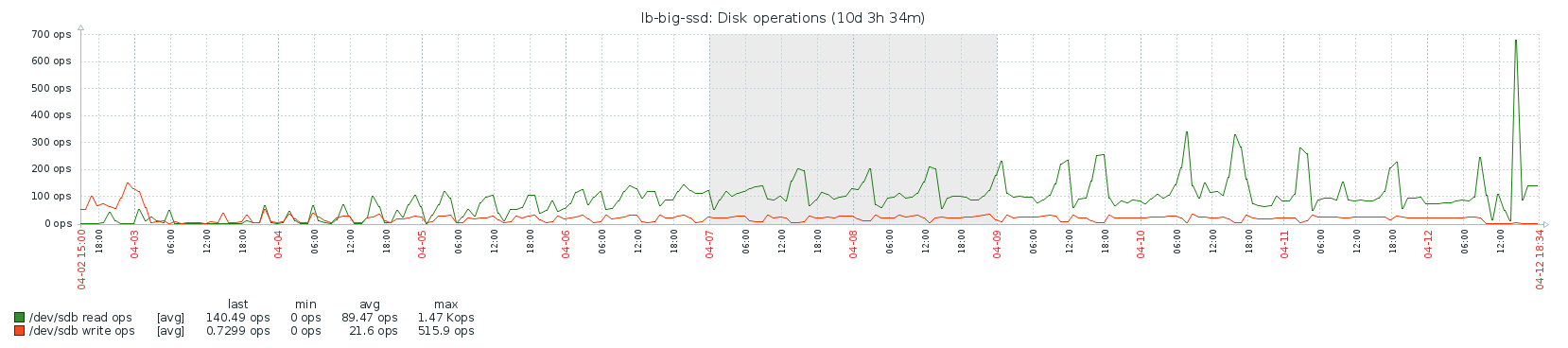
Disk
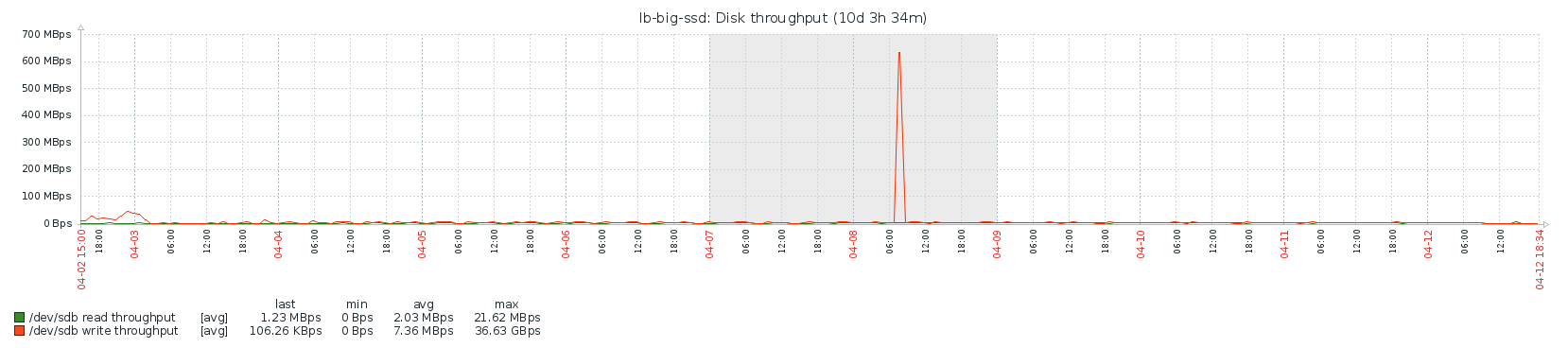
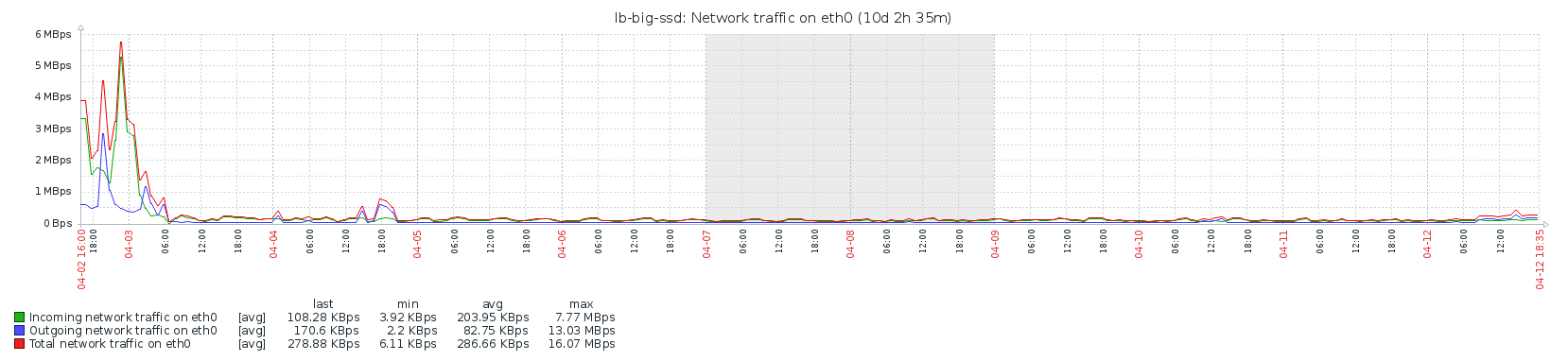
Network
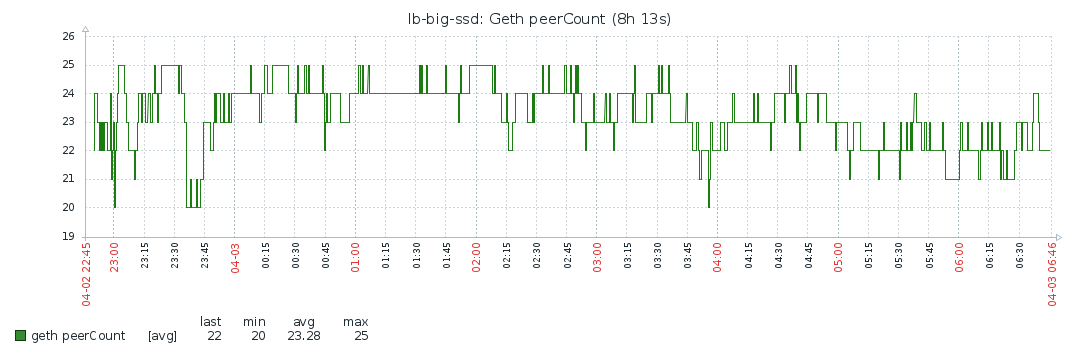
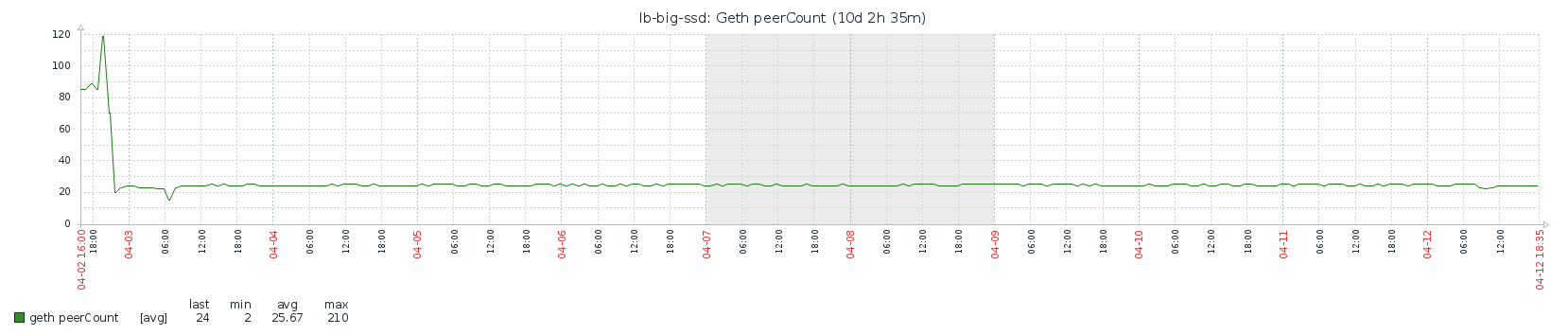
Peers
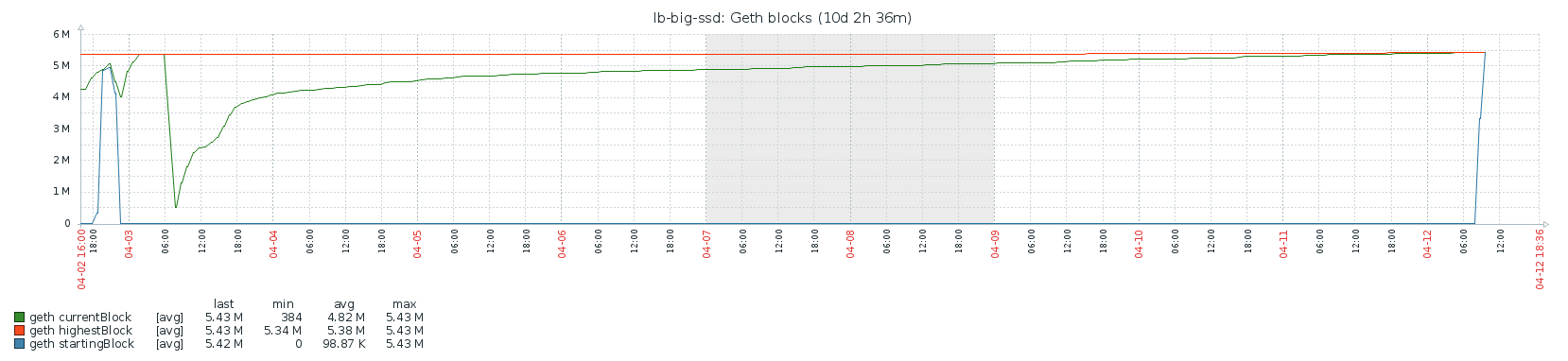
Blocks
Notes
I guess the notes around peers still stand, though I didn’t test that explicitly for full sync:
- Firewall needs to be open for port 30303 (I opened both UDP and TCP). Otherwise you won’t get enough peers.
- Syncing actually seems to take more time with more peers. I settled on the default of 25. With 100 peers it was much slower.
Conclusions
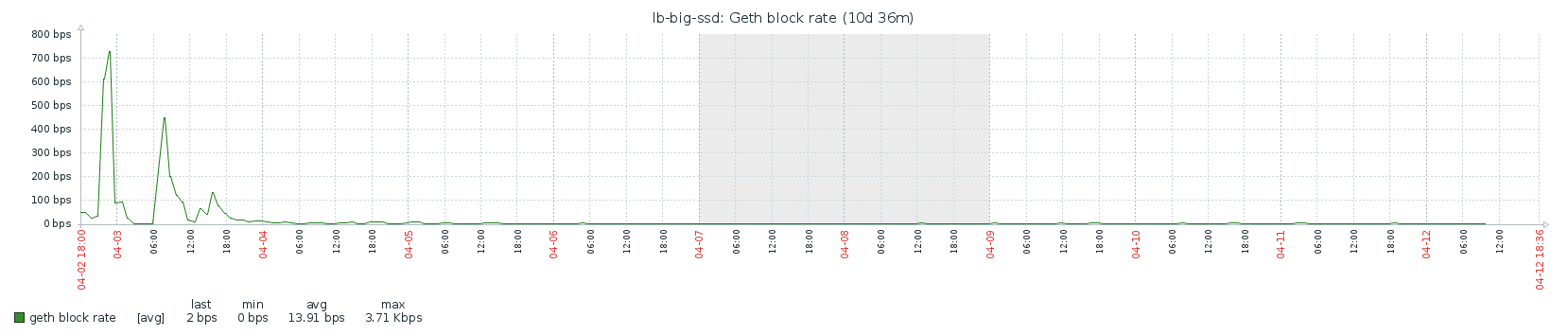
Clearly, doing a full sync takes much longer than a fast sync: over 9 days vs about 8 hours. From my data, it looks like CPU is the bottleneck here. What surprises me is that the block rate is very “bursty”. The following patterns repeats itself over the course of the entire sync:
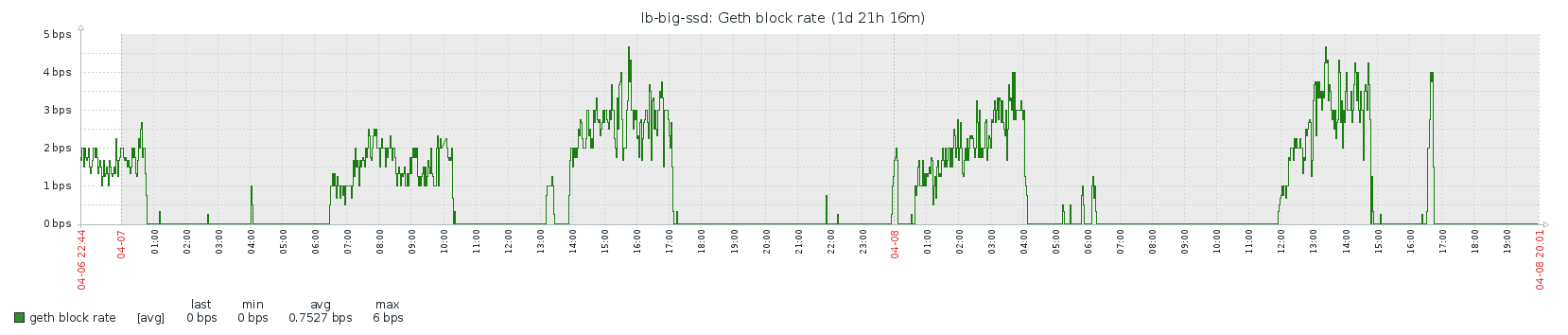
I would expect the block rate to be fairly constant if the CPU is the bottleneck. I don’t think the availability of blocks on the network is the problem here since the fast sync also needs all the blocks, and that happened within 8 hours. I do see some correlation with memory activity, but I didn’t dive in it any more. If someone has any ideas, I’d love to hear!
What also surprises me is that all the Ethereum data is already larger than the entire Bitcoin data directory (about 200GB), while Bitcoin is almost 3 times older than Ethereum. Clearly, Ethereum grows much faster than Bitcoin. I guess that it’ll become even harder to do full syncs in the future, and that will probably mean the number of full nodes will decrease. That can’t be good.
Hope this post was of some help. If you have results to share, please let me know.
Anatomy of a geth –fast sync
I’ve been reading up on Ethereum for the last couple of days. Apparently, doing the initial sync is one of the major issues people run into (at least with geth). That includes me. I first tried syncing on an HDD, and that didn’t work. I then used a mediocre machine with SSD, but it still kept on running with no apparent end in sight. So I decided to use a ridiculously large machine on Azure and sync there. Turns out that with this machine is was able to do a –fast sync in a little under 8 hours.
Specs
I used an Azure Standard_L16s storage optimized VM. This beast has 16 cores, 128 gigs of memory and 80,000 IOPS and 800MBps throughput on its temporary storage disk. Ought to be enough you’d say. I started geth with ./geth --maxpeers 25 --cache 64000 --verbosity 4 >> geth.log 2>&1
Overview
| Azure VM Instance | Standard_L16s |
| OS | Ubuntu 16.04.4 LTS |
| CPU | 16 cores |
| Memory | 128GB |
| Disk IOPS (spec) | 80,000 |
| Disk throughput (spec) | 800 MBps |
| Geth version | geth-linux-amd64-1.8.3-329ac18e |
| Geth maxpeers | 25 |
| Geth cache | 64,000MB |
Results
| Start time | 2 apr 2018 20:46:43 UTC |
| End time * | 3 apr 2018 04:27:15 UTC |
| Total duration | 7h 40m 32s |
| Imported blocks at catch up time | 5,369,956 |
| Blocks caught up | 3 apr 2018 00:11:08 (3h 24m 25s) |
| Total imported state trie entries | 114,566,252 |
| State caught up | 3 apr 2018 04:24:07 (7h 37m 24s) |
| du -s ~/.ethereum | 77,948,852 |
* End time defined as first single-block “Imported new chain segment” log message
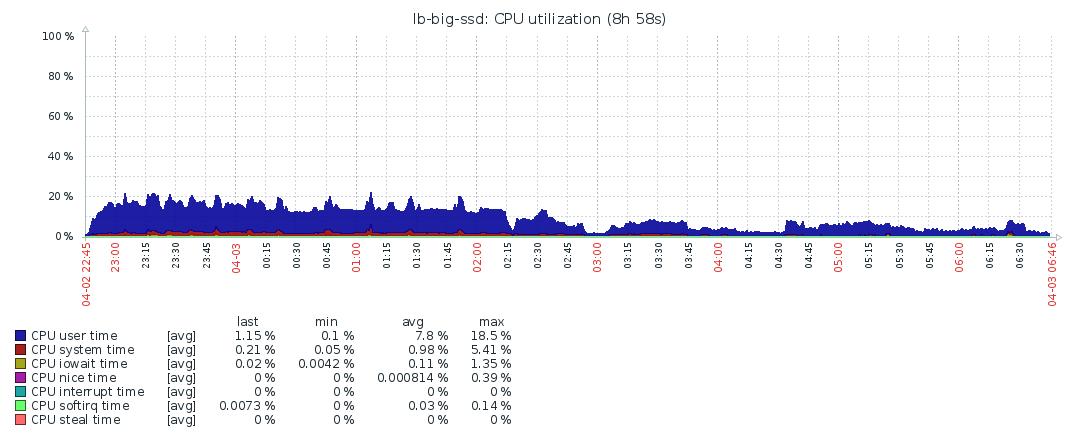
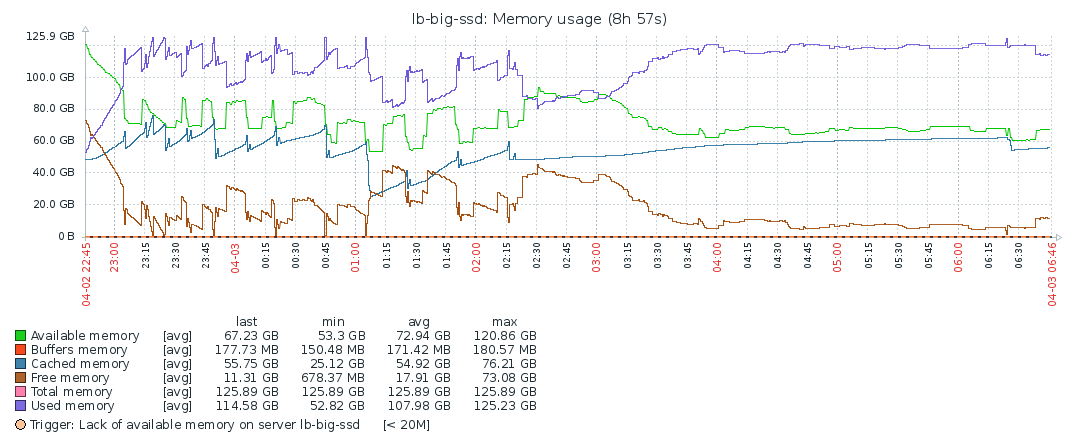
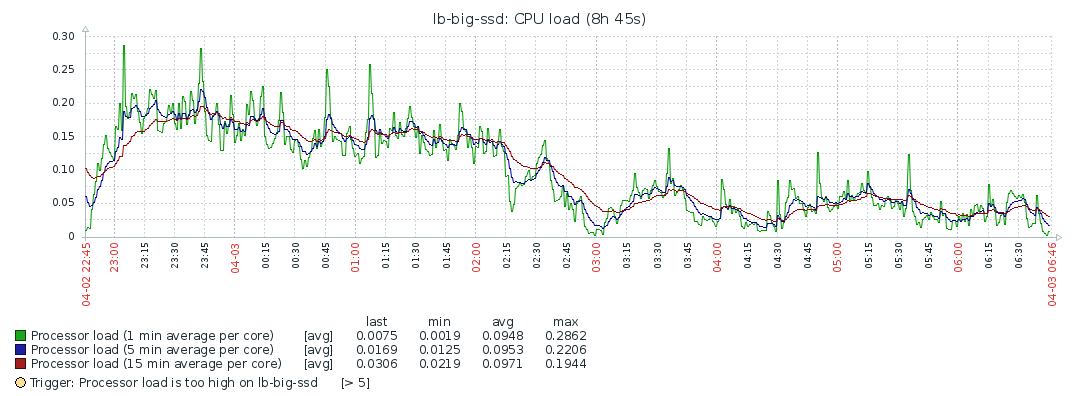
CPU/Load/Memory
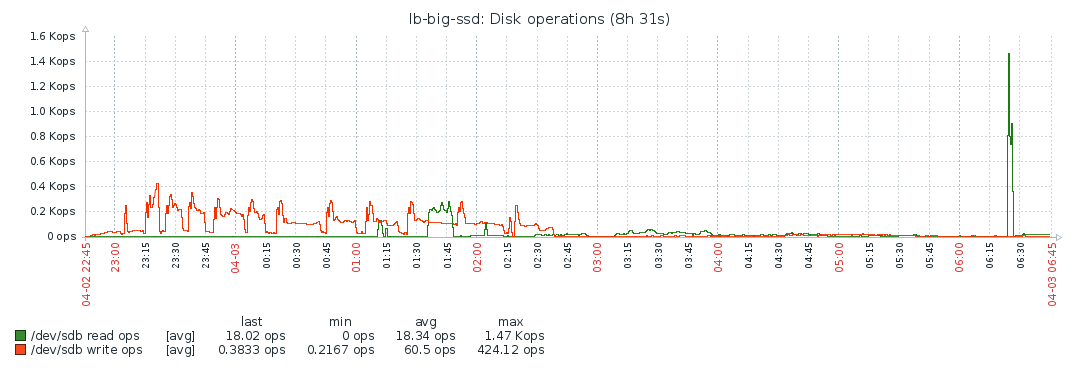
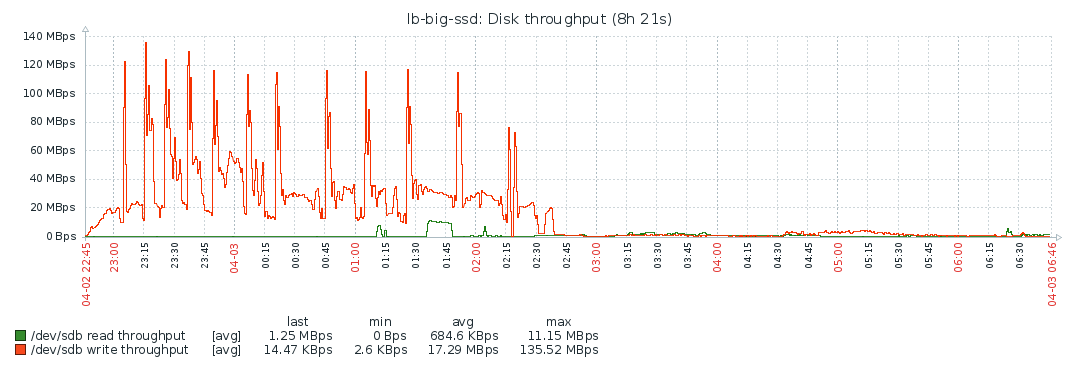
Disk
Network
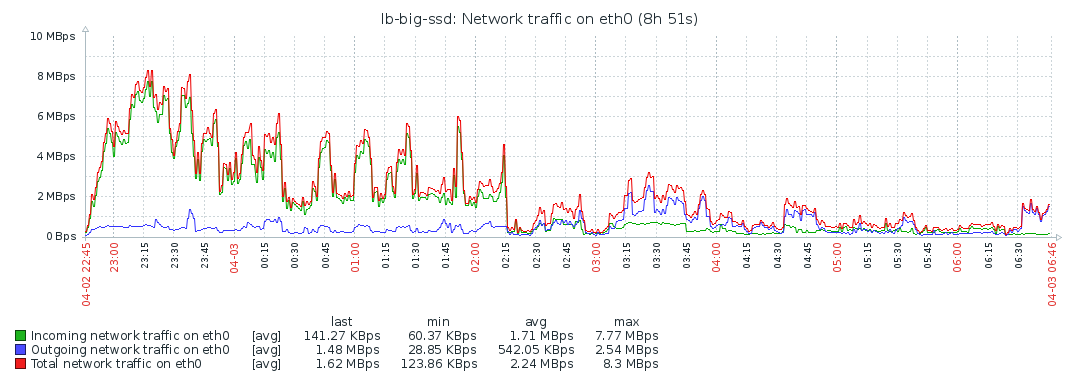
Peers
Blocks
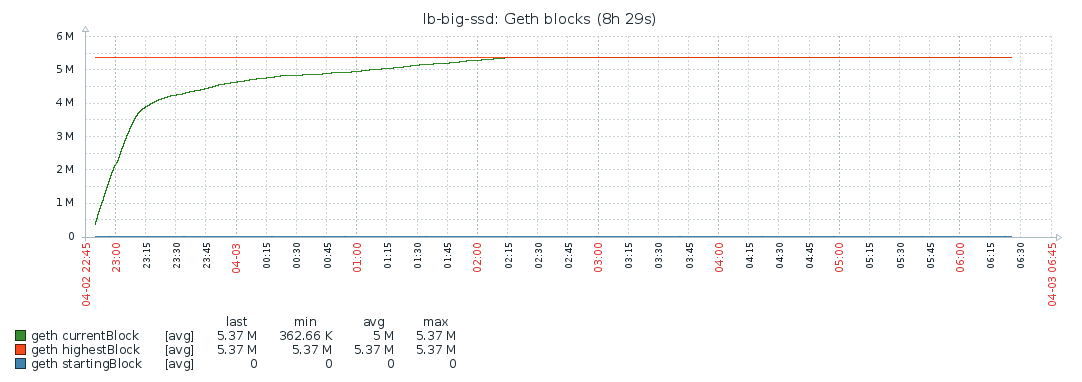
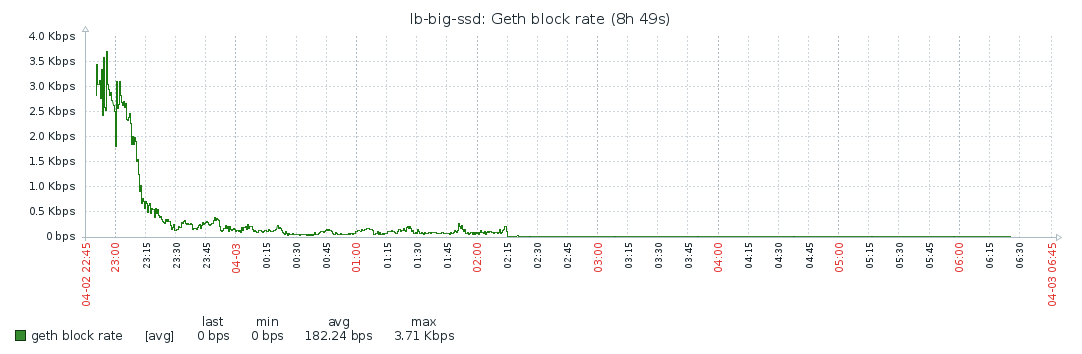
State trie
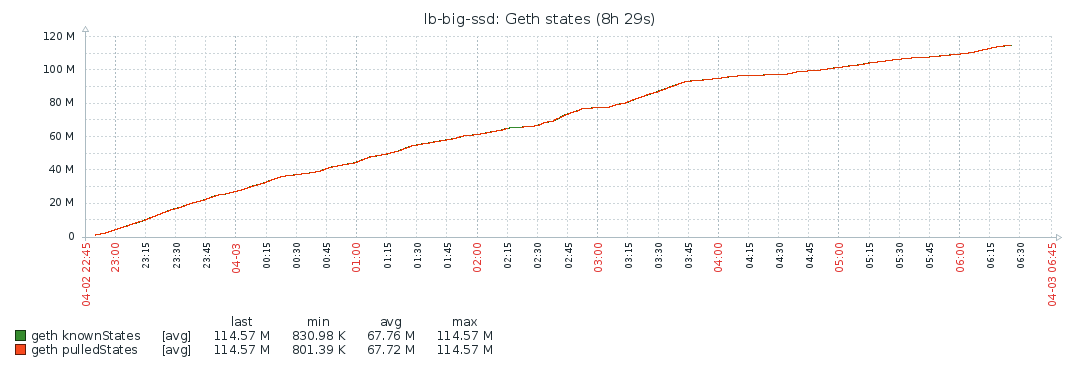
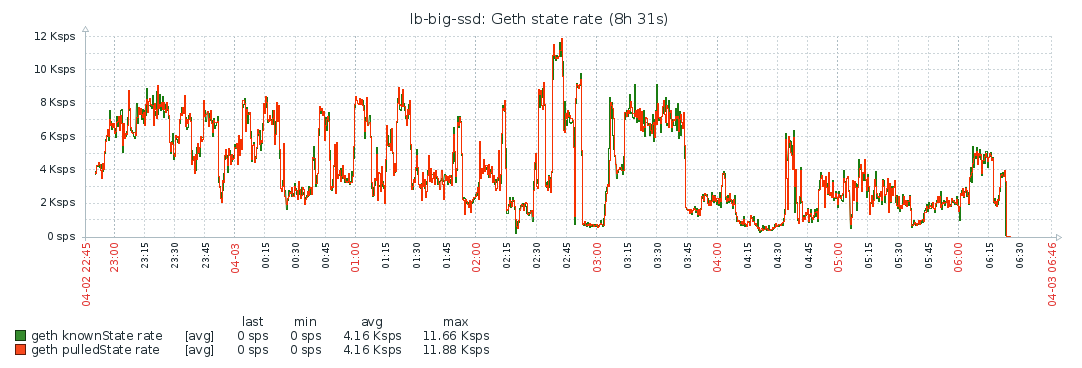
Notes
- Firewall needs to be open for port 30303 (I opened both UDP and TCP). Otherwise you won’t get enough peers.
- Syncing actually seems to take more time with more peers. I settled on the default of 25. With 100 peers it was much slower.
- Importing the chain segments did not take significant time, contrary to the comment mentioned in the github issue.
Conclusions
Disk IO is mostly used while fetching the blocks. After that, the system’s resources are barely used, which makes me think the bottleneck is the network. Though even during block syncing, the resources are barely maxed out, so probably the process is constrained by the network the entire time. I’m not familiar enough with Geth/Ethereum to ascertain this for sure though. As stated above, increasing the number of peers didn’t improve the situation, but made it worse.
Hope this post was of some help. If you have results to share, please let me know.
Turning Apache Authentication in an OpenID Connect Provider
I wrote a small PHP application to turn Apache into an OpenID Connect Provider: https://github.com/FreekPaans/apache-openid-connect. This is useful if you have an existing environment where you authenticate via HTTP Basic Authentication, and want to use that authentication in other environments as well.