We had an Event Sourcing coding dojo at Infi this Tuesday. Turnout was 18 people, half of them being Infi employees, the others enthusiastic community members. The dojo was a big success: we had a lot of fun, learned new stuff, met new people and had a great discussion afterwards. I’m really happy about this 🙂
For this dojo we prepared a custom version of NerdDinner, the canonical ASP.NET MVC example app, so it could act as a playground for experimenting with event sourcing. To support event sourcing we made these modifications:
- Added basic infrastructure for raising events (the Event, Event<T>, IEventData and EventScope types)
- Load events when hydrating a Dinner entity (DinnerRepository.Find)
- Added DbSet<Event> to the NerdDinners DbContext to add a table for storing Events to disk
- Have a hook for the NerdDinners DbContext intercepting published Events (NerdDinners.OnEventsPublished)
- Removed mocking from the unit tests so that you could run the tests against the DB
- Implemented RSVPing using Event Sourcing (RSVPController.Register)
All event handling is done synchronously, so you don’t have to bother with eventual consistency and all that stuff, instead you can just focus on the core event sourcing concepts. Also, the result is actually a hybrid mutable state / ES solution, since there’s still some data stored in table rows. We didn’t feel it was worth the effort to completely move to event sourcing for this dojo, though it might be a fun exercise. You can have a look at the code on github. Please note that this infrastructure is not production-ready nor production-tested, so keep that in mind if you want to base your own infra on this code.
The exercises
With the above code available at the start of the dojo, we set up a couple of exercises for pairs to tackle during the evening.
Spoiler alert: the following description of the exercises might contain partial answers to the exercises; if you want to do the dojo please consider doing that first.
1. Cancel your RSVP
With RSVPing already in place, canceling is the next logical step. In this exercise you can explore how event sourcing works in the RSVP case, and try to apply that to canceling. It ends up being more or less a copy-paste exercise, but one that lets you quickly explore the various steps involved.
2. Show a dinner activity feed
In the dinners details screen we’d like to show an activity history, with entries for RSVPs, cancelled RSVPs, location changes, etc. This is very easy to implement using event sourcing, but hard using mutable state based persistence. In fact, in the latter case you probably end up persisting event-like things. The goal of the exercise is to show how event sourcing helps you do useful stuff that is otherwise hard to implement.
3. Change the address for a Dinner
In the original application, updating details for the dinner was very CRUD-y. You would have one form in which all details could be edited and then saved. This approach doesn’t work particularly well with event sourcing since you’d usually want the events to express more intent than just “Dinner Changed”. To do so, you usually build a task-based UI, with explicit commands for certain (domain) operations. In this exercise that domain operation was changing the address of the Dinner (in hindsight the operation maybe should’ve been called ChangeVenue). The goal was showing how using event sourcing might end up requiring changes to the UI.
4. Optimize the popular dinners query
The NerdDinner UI has a list of popular dinners:
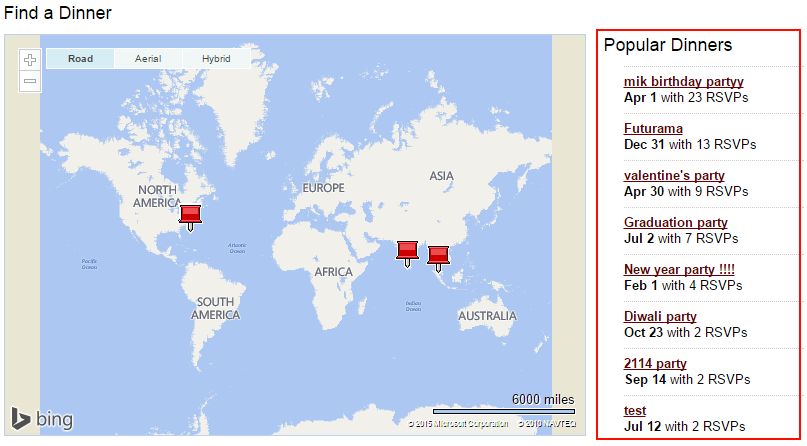
It’s a list of dinners sorted by RSVP count descending. Producing this list efficiently with event sourcing is harder than in a mutable state based scenario, because we don’t have the current state readily available to query on. Since we now need to sort globally on all dinners, we would have to fetch all dinners and events and then do the sort entirely in memory. That could become a problem if we have a lot of dinners in our system.
So in this exercise the goal was to listen to the RSVPed and RSVPCanceled events and build a separate read model for keeping the count of RSVPs per dinner, and use that to sort the list. We expected this exercise to take most time, but a few pairs managed to finish the exercise within the allotted time (about 2.5 hours for all exercises).
Please do try this at home!
All in all, I think doing the above exercises could be a good introduction to event sourcing, and most of the people that attended agreed.
So, if you want to try out event sourcing at your company or just want to experiment with it yourself, doing this dojo might be a great way to start. Just clone the code and try doing the exercises (all exercises have accompanying tests to get you started). Please let me know about your results 🙂