I wrote about the dependency inversion principle (DIP) a couple of weeks ago and got some questions about the practical implementation issues when applying it in a .NET environment, specifically how to apply it when using Entity Framework (EF). We came up with three solutions, which I’ll detail in this post.
Note that even though this post is written for EF, you can probably easily extrapolate these strategies to other data access tools such as NHibernate, Dapper or plain old ADO.NET as well.
Recap: Dependency Inversion for data access
Our goal is to have our data access layer depend on our business/domain layer, like this:
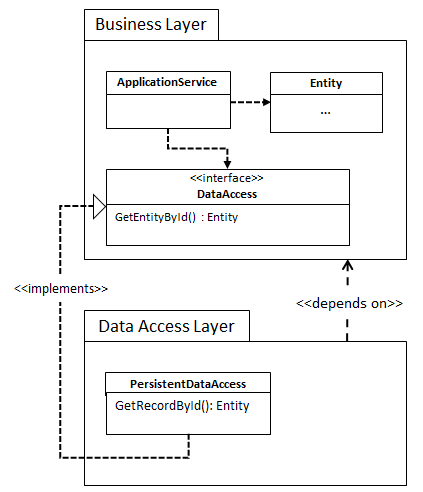
When trying to implement this with EF, you’ll run into an interesting issue: where do we put our entity classes (the classes representing the tables)? Both the business layer and data access layer are possible, and there are trade-offs to both. We’ve identified three solutions that we find viable in certain circumstances, and that’s exactly the topic of this post.
Strategy 1: Entities in DAL implementing entity interface
For the sake of this post we’ll use a simple application that handles information about Users. The Users are characterized by an Id, Name and Age. The business layer defines a UserDataAccess that allows the ApplicationService classes to fetch a user by its id or name, and allows us to persist the user state to disk.
Our first strategy is to keep the definition of our entity classes in the DAL:
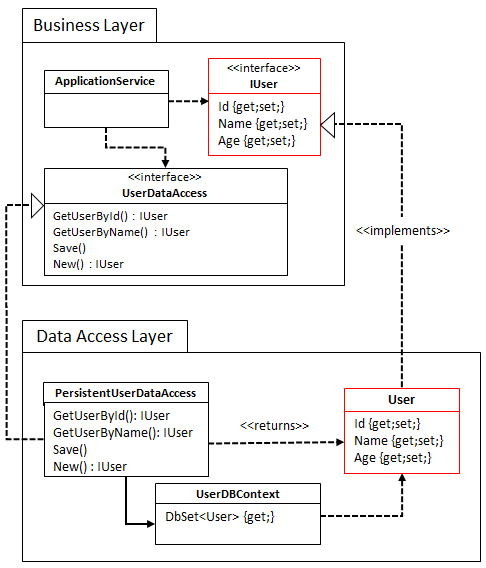
Note that we need to introduce an IUser interface in the business layer since the dependency runs from DAL to business. In the business layer we then implement the business logic by working with the IUser instances received from the DAL. The introduction of IUser means we can’t have business logic on the User instances, so logic is moved into the ApplicationService classes, for example validating a username:
public class UserApplicationService {
public void ChangeUsername(int userId,string newName) {
AssertValidUsername(newName);
var user = _dataAccess.GetUserById(userId);
user.Name = newName;
_dataAccess.Save();
}
public int AddUser(string withUsername,int withAge) {
AssertValidUsername(withUsername);
var user = _dataAccess.New();
user.Age = withAge;
user.Name = withUsername;
_dataAccess.Save();
return user.Id;
}
private static void AssertValidUsername(string withUsername) {
if(string.IsNullOrWhiteSpace(withUsername)) {
throw new ArgumentNullException("name");
}
}
...
}
Note that this is pretty fragile since we need to run this check every time we add some functionality that creates or updates a username.
One of the advantages of this style is that we can use annotations to configure our EF mappings:
class User : IUser{
[Key]
public int Id {get;set;}
[Index(IsUnique=true)]
[MaxLength(128)]
[Required]
public string Name {get;set;}
public int Age{get;set;}
}
A peculiarity of this solution is how to handle adding users to the system. Since there is no concrete implementation of the IUser in the business layer, we need to ask our data access implementation for a new instance:
public class UserApplicationService {
public int AddUser(string withUsername, int withAge) {
var user = _dataAccess.New();
user.Age = withAge;
user.Name = withUsername;
_dataAccess.Save();
return user.Id;
}
...
}
public class PersistentUserDataAccess : UserDataAccess{
public IUser New() {
var user = new User();
_dbContext.Users.Add(user);
return user;
}
...
}
The addition of the new User to the context together with the fact that Save doesn’t take any arguments is a clear manifestation that we expect our data access implementation to implement a Unit of Work pattern, which EF does.
It should be clear that this style maintains a pretty tight coupling between the database and object representation: our domain objects will almost always map 1-to-1 to our table representation, both in its names and its types. This works particularly well in situations where there isn’t much (complex) business logic to begin with, and we’re not pursuing a particularly rich domain model. However, as we’ve already seen, even with something as simple as this we can already run into some duplication issues with the usernames. I think in general this will lead you to a more procedural style of programming.
The full source to this example is available in the DIP.Interface.* projects on GitHub.
Strategy 2: Define entities in the business layer
Our second strategy defines the User entities directly in the business layer:
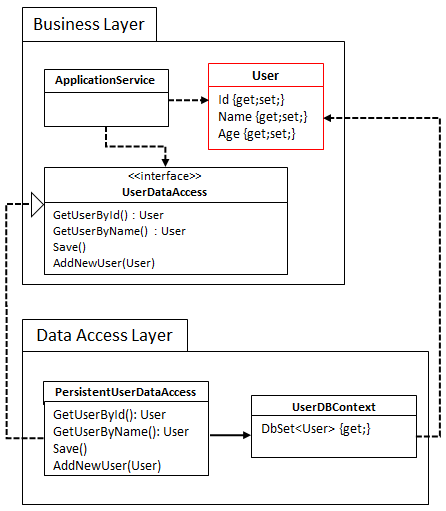
The current version of EF (6.1) handles this structure without problems, but older versions or other ORMs might not be so lenient and require the entities to be in the same assembly as the DbContext.
An advantage of this strategy is that we can now add some basic logic to our User objects, such as the validation we had earlier:
public class User {
public string Name {
get {
return _name;
}
set {
if(string.IsNullOrWhiteSpace(value)) {
throw new ArgumentNullException("name");
}
_name = value;
}
}
...
}
We now cannot use annotations to configure our mapping anymore, so we have to configure it through the EF fluent API to achieve the same result:
class UserDbContext : DbContext{
public DbSet Users{get;set;}
protected override void OnModelCreating(DbModelBuilder modelBuilder) {
base.OnModelCreating(modelBuilder);
modelBuilder.Entity()
.HasKey(_=>_.Id)
.Property(_=>_.Name)
.HasMaxLength(128)
.IsRequired()
.HasColumnAnnotation("Index",
new IndexAnnotation(
new IndexAttribute() {
IsUnique = true
}));
}
}
I think this is probably a bit less clean and discoverable than the annotated version, but it’s still workable.
The method of adding new Users to the system also changes slightly: we now can instantiate User objects within the business layer, but need to explicitly add it do the unit of work by invoking the AddNewUser method:
public class UserApplicationService {
public int AddUser(string withUsername, int withAge) {
var user = new User {
Age = withAge,
Name = withUsername
};
_dataAccess.AddNewUser(user);
_dataAccess.Save();
return user.Id;
}
...
}
public class PersistentUserDataAccess : UserDataAccess{
public void AddNewUser(User user) {
_context.Users.Add(user);
}
...
}
Just as with strategy 1, there is still a large amount of coupling between our table and object structure, having the same implications with regard to programming style. We did, however, manage to remove the IUser type from the solution. In situations where I don’t need a rich domain model, I favor this strategy over the previous one since I think the User/IUser stuff is just a little weird.
The full source to this example is available in the DIP.EntitiesInDomain.* projects on GitHub.
Strategy 3: Map the entities to proper domain objects
In this case we decouple our DAL and business layer representation of the User completely by introducing a Data Mapper:
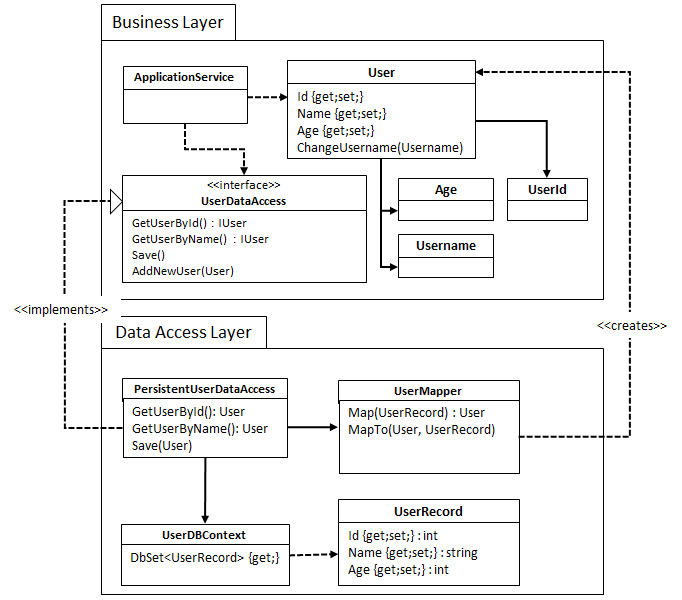
This is the most flexible solution of the three: we’ve completely isolated our EF entities from our domain objects. This allows us to have properly encapsulated, behavior-rich business objects, which have no design compromises due to data-storage considerations. It is, of course, also more complex, so use it only when you actually need the aforementioned qualities.
Validation of the username is now done in the Username factory method, and is not a responsibility of the User object at all anymore:
public struct Username {
public static Username FromString(string username) {
if(string.IsNullOrWhiteSpace(username)) {
throw new ArgumentNullException("name");
}
return new Username(username);
}
...
}
public class User {
public Username Name { get; private set; }
public UserId Id { get; private set; }
public Age Age { get; private set; }
...
}
Using rich domain objects like this is extremely hard (if at all possible) with the other strategies, but can also be extremely valuable when designing business-rule heavy applications (instead of mostly CRUD).
Actually persisting Users to disk is also completely different with this strategy, since we can’t leverage EF’s change tracking/unit of work mechanisms. We need to explicitly tell our UserDataAccess which object to save and map that to a new or existing UserRecord:
public class UserApplicationService {
public void ChangeUsername(UserId userId, Username newName) {
var user = _dataAccess.GetUserById(userId);
user.ChangeUsername(newName);
_dataAccess.Save(user);
}
...
}
public class PersistentUserDataAccess:UserDataAccess {
public void Save(User user) {
if(user.IsNew) {
SaveNewUser(user);
return;
}
SaveExistingUser(user);
}
private void SaveExistingUser(User user) {
var userRecord = _context.Users.Find(user.Id.AsInt());
_userMapper.MapTo(user,userRecord);
_context.SaveChanges();
}
private void SaveNewUser(User user) {
var userRecord = new UserRecord {};
_userMapper.MapTo(user,userRecord);
_context.Users.Add(userRecord);
_context.SaveChanges();
user.AssignId(UserId.FromInt(userRecord.Id));
}
...
}
In general, this style will be more work but the gained flexibility can definitely outweigh that.
The full source to this example is available in the DIP.DataMapper.* projects on GitHub.
Conclusion
In this post we explored 3 strategies for applying the Dependency Inversion principle to Entity Framework in .NET based applications. There are probably other strategies (or mixtures of the above, specifically wrapping EF entities as state objects in DDD) as well, and I would be happy to hear about them.
I think the most important axis to evaluate each strategy on is the amount of coupling between database schema and object structure. Having high coupling will result in a more easy/quick-to-understand design, but we won’t be able to design a really rich domain model around them and lead you to a more procedural style of programming. The 3rd strategy provides a lot of flexibility and does allow for a rich model, but might be harder to understand at a first glance. As always, the strategy to pick depends on the kind of application you’re developing: if you’re doing CRUDy kind of work, perhaps with a little bit of transaction script, use one of the first 2. If you’re doing business-rule heavy domain modelling, go for the 3rd one.
All code (including tests) for these strategies is available on GitHub.